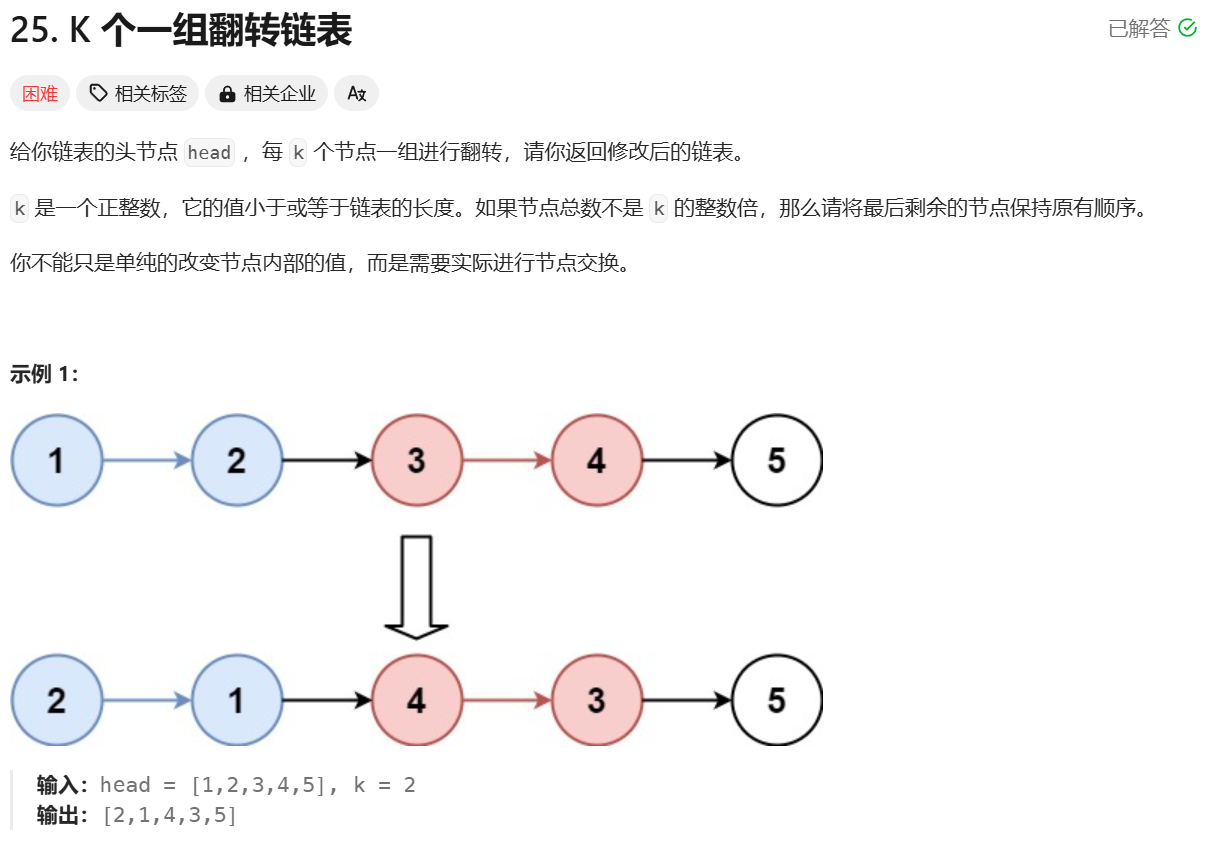
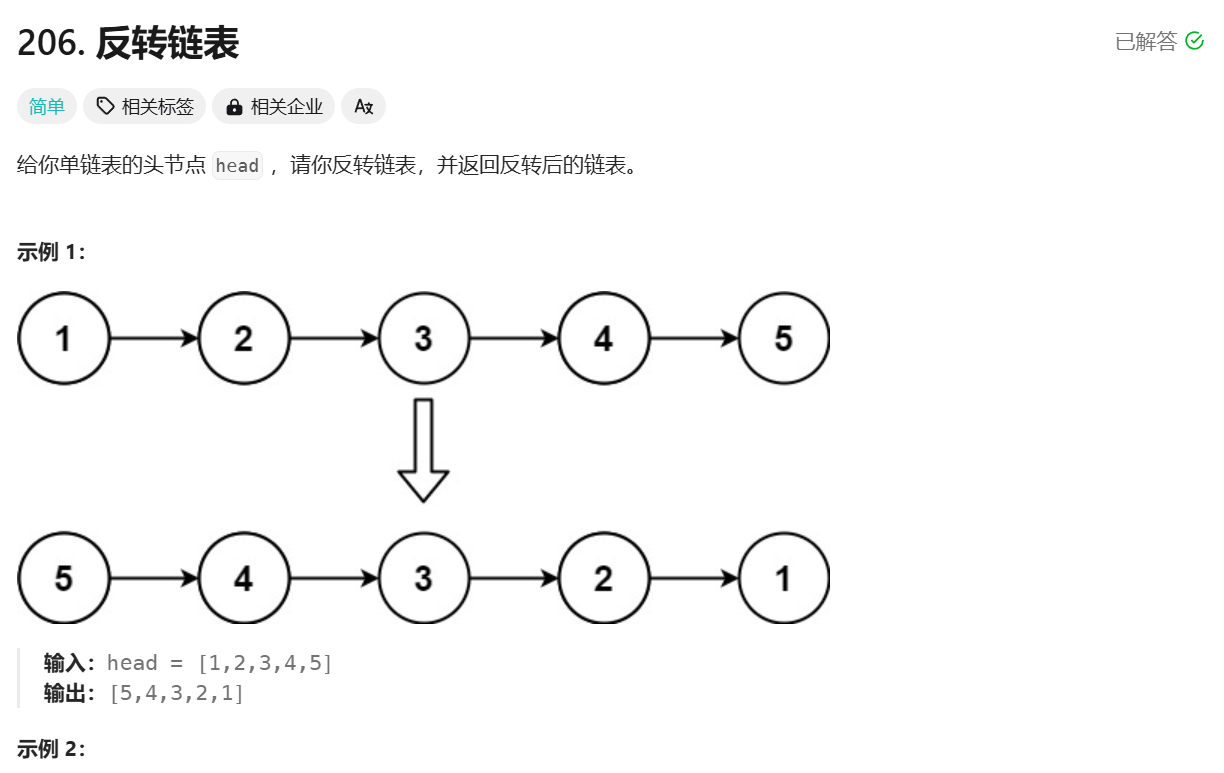
本文最后更新于 370 天前。

我们考虑枚举数组中的每个数 x,考虑以其为起点,不断尝试匹配 x+1,x+2,⋯ 是否存在,假设最长匹配到了 x+y,那么以 x 为起点的最长连续序列即为 x,x+1,x+2,⋯,x+y,其长度为 y+1,我们不断枚举并更新答案即可。
对于匹配的过程,暴力的方法是 O(n) 遍历数组去看是否存在这个数,但其实更高效的方法是用一个哈希表存储数组中的数,这样查看一个数是否存在即能优化至 O(1) 的时间复杂度。
仅仅是这样我们的算法时间复杂度最坏情况下还是会达到 O(n2)(即外层需要枚举 O(n) 个数,内层需要暴力匹配 O(n) 次),无法满足题目的要求。但仔细分析这个过程,我们会发现其中执行了很多不必要的枚举,如果已知有一个 x,x+1,x+2,⋯,x+y 的连续序列,而我们却重新从 x+1,x+2 或者是 x+y 处开始尝试匹配,那么得到的结果肯定不会优于枚举 x 为起点的答案,因此我们在外层循环的时候碰到这种情况跳过即可。
那么怎么判断是否跳过呢?由于我们要枚举的数 x 一定是在数组中不存在前驱数 x−1 的,不然按照上面的分析我们会从 x−1 开始尝试匹配,因此我们每次在哈希表中检查是否存在 x−1 即能判断是否需要跳过了。
增加了判断跳过的逻辑之后,时间复杂度是多少呢?外层循环需要 O(n) 的时间复杂度,只有当一个数是连续序列的第一个数的情况下才会进入内层循环,然后在内层循环中匹配连续序列中的数,因此数组中的每个数只会进入内层循环一次。根据上述分析可知,总时间复杂度为 O(n),符合题目要求。空间复杂度O(n)。哈希表存储数组中所有的数需要O(n)的空间。
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> num_set;
for(const int& num : nums ){
num_set.insert(num);
}
int ans = 0;
for(const int& num: num_set){
if(!num_set.count(num - 1)){
int cnt = 1;
while(num_set.count(num + cnt)){
cnt++;
}
ans = max(ans, cnt);
}
}
return ans;
}
};